
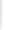


Mensch versus KI: Ärzte sind immer besser
|
|
| Arzt und Patient: Große KI-Sprachmodelle haben hier das Nachsehen (Foto: Max, pixabay.com) |
Cleveland (pte003/04.04.2024/06:10) - Generative Künstliche Intelligenz (KI) kann zwar viel, doch kann diese Ärzte bis auf weiteres nicht ersetzen. Andrei Brateanu von der Abteilung für Innere Medizin der Cleveland Clinic Foundation ( https://my.clevelandclinic.org/ ) und sein Team haben getestet, wie gut die medizinischen Ratschläge von GPT-4 und Google Gemini sind, die zur Kategorie "große Sprachmodelle" (LLM) gehören. Sie geben auf Fragen ausgefeilt formulierte Antworten, die auf Informationen aus dem Internet basieren.
Überzeugend, aber falsch
"Große Sprachmodelle bieten medizinische Informationen an, die logisch und überzeugend aussehen, auch wenn sie ungenau oder falsch sind. Daher hielten wir es für wichtig, die Antworten von LLMs mit den Daten anerkannter medizinischer Organisationen zu vergleichen. Dieser Vergleich trägt dazu bei, die Zuverlässigkeit der medizinischen Informationen zu überprüfen, indem sie mit vertrauenswürdigen Gesundheitsdaten abgeglichen werden", so Brateanu.
Die Forscher haben OpenAIs GPT-4 und Gemini 56 Fragen gestellt. Die Antworten überprüften zwei Ärzte auf ihre Richtigkeit. Ein dritter Arzt griff bei unterschiedlichen Auffassungen ein, um Unstimmigkeiten zu klären. Fazit: 28,6 Prozent der Antworten von GPT-4 waren richtig, 28,6 Prozent ungenau und 42,8 Prozent teilweise richtig, aber unvollständig. Gemini schnitt besser ab: 53,6 Prozent der Antworten waren richtig, 17,8 Prozent ungenau und 28,6 Prozent teilweise richtig.
Sprachmodelle unperfekt
"Alle LLMs, einschließlich GPT-4 und Gemini, arbeiten mit komplexen mathematischen Algorithmen. Die Tatsache, dass beide Modelle ungenaue Antworten lieferten oder wichtige Infos ausließen, unterstreicht die anhaltende Herausforderung, KI-Tools zu entwickeln, die zuverlässige medizinische Ratschläge geben können. Diese Notwendigkeit mag überraschen, wenn man die fortschrittliche Technologie hinter diesen Modellen und ihre voraussichtliche Rolle im Gesundheitswesen bedenkt", mewint Brateanu.
Die Ergebnisse des Tests zeigen, wie wichtig es ist, bei medizinischen Infos aus KI-Quellen vorsichtig und kritisch zu sein. Es ist demnach stets nötig, medizinisches Fachpersonal zu konsultieren, um genaue medizinische Ratschläge zu erhalten. Für die Angehörigen der Gesundheitsberufe zeigen sie das Potenzial und die Grenzen des Einsatzes von KI als ergänzendes Instrument bei der Patientenversorgung auf und unterstreichen die Notwendigkeit, von KI-generierte Infos zu überprüfen.
(Ende)
|
|
|
So wurde bewertet: |
Weitersagen |
|
|
|
|

PORR rechnet mit anhaltender Baukonjunktur
30.10.2024